-_Disaster_Recovery_(DR)_strategy_is_crucial_for_Video_Data_safekeeping_&_Business_Continuity.webp)
Business operations and productivity of organizations are greatly connected to their IT infrastructure, including servers, storage, network, user systems, and the applications used. Data Centre (DC), a facility that houses a large group of networked computer servers, is largely used by organizations for storing, processing & distribution of data and applications. Hence, creating strategies and a framework for maintaining operations in case of any downtime or even a disaster at the data centre (DC) is no longer an option. Disaster Recovery (DR) framework puts an organization’s operations paramount and is a part of comprehensive business continuity plans.
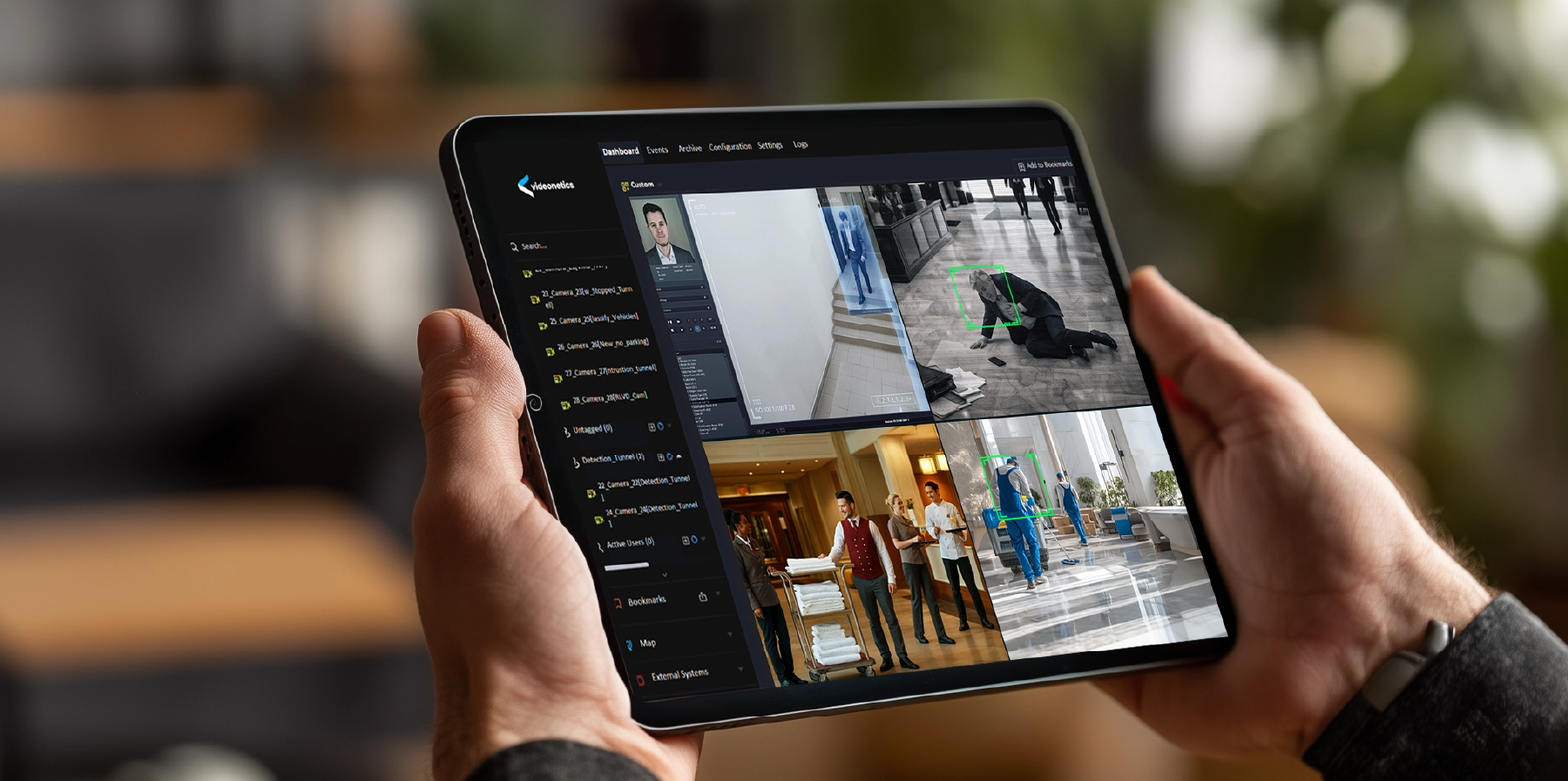
In the Video surveillance domain, unlike a transactional system, the main challenge lies in handling huge volumes of data generated due to video files and protecting them from loss or corruption. The transfer of video data from one location to another demands a significant amount of network bandwidth, which may or may not be readily available. Therefore, traditional strategies for data protection and general techniques of business continuity in the case of Data Centre (DC) failure cannot be applied, as it is in the domain of video surveillance.
DC- DR armature is designed to minimize data loss in case the primary data centre (DC) fails to operate and becomes inoperable for a certain duration of time. Two primary factors determine the DC- DR performance criterion.
1. The Recovery Point Objective (RPO) - This is defined as the outside quested period in which data might be lost from an IT service due to a disaster (or disruption).
2. Recovery Time Objective (RTO) - This is defined as the targeted duration of time and a service level within which business processes must be restored after a disaster to avoid the terrible consequences associated with a break in business continuity.
Services provided by DC-DR architecture can be categorized into three service groups:
A. Data Safe-keeping - This refers to the protection of data that has already been generated by data centres. Data that is already recorded and stored in the data centres (DC) must be replicated, in parts or in full, to ensure that even if the data centre (DC) fails beyond repair, data is always available to users. Data Centres (DC) may choose to replicate any data that it owns (based on user configuration) and send requests accordingly to the replication server.
B. Fault tolerance through parallelism - This includes services related to fault tolerance through active-active configuration. For some critical activities, both DC and DR should be active in parallel (active-active mode), so that even if the data centre (DC) fails to render some critical services, the services are available from the disaster recovery (DR) setup. For example, if a data-source is active but the data centre (DC) is unable to capture the data due to application or infrastructure failure, the disaster recovery (DR) system can capture the data in its system. Fault tolerance through parallelism essentially means deploying a full-fledged Video Management Software system at DR, with some metadata sync in the data centre (DC). The synchronization must be with respect to camera IDs, camera names, camera locations etc.
C. Business continuity - This includes services related to the continuation of business. The services offered by data centres (DC) should be available, either in full or in limited form, from Disaster Recovery (DR) in case of the former’s failure. For example, the system should allow live monitoring of a subset of cameras even when the data centre (DC) is unserviceable. When disaster recovery (DR) runs in parallel, the VMS system must be available to assigned users if DC fails.
The generalities of failover & disaster recovery are constantly misinformed and used interchangeably in different surroundings and environments. Like failover, disaster recovery is vital to data vacuity & durability of operations. Failover is more like a spare wheel, vastly executed to handle failures or outages that are less severe and in installations that are not large in terms of volume of data and services. Disaster Recovery is more applicable and considerably espoused in the case of large-scale infrastructural outages. Simply put, the concept of DR implicates restoring all services to their primary and default states. It encompasses failover systems and high-data vacuity protocols.